از جنگ کره تا کاهش عزت نفس عمومی
| دوشنبه, ۱ فروردين ۱۴۰۱، ۰۲:۵۴ ب.ظ |
۰ نظر
سال ۱۹۵۰ کیم ایل سونگ رهبر وقت کره شمالی دستور حمله به کره جنوبی رو میده .
سال ۱۹۵۰ کیم ایل سونگ رهبر وقت کره شمالی دستور حمله به کره جنوبی رو میده .
از نصف شب گذشته، همه لامپهای اتاقم رو خاموش کردم به جز نور چراغ مطالعه و صفحه مانیتورم. تنها صدایی که میاد صدای سوختن بخاری هست و من دارم این پست رو مینویسم. در سریال HIMYM دیده بودم که شخصیت اصلی داستان گفته بود هیچ وقت کار مهمی رو بعد از نصف شب انجام نده. شما هم با دید اینکه حالا خوابش میومده یکسری حرف هم زده بخونید و نه بیشتر.
یادمه درسی داشتم که بنظرم استادش اصلا خوب درس نمیداد و نه مثال و تمرین عملی حل میکرد نه قسمت های جالب از روی کتاب رو درس میداد نه اینکه حداقل یک چیزی یادمون بده که بدردمون بخوره. تنها بشین سر کلاس و اسلاید های سال های قبل رو گوش بده کلاس هم اول و آخرش به بطالت می گذشت. بعد از ثبت نمرهها همون دانشجوهایی که پشت سرش ازش بد تعریف میکردن اومدن تو گروه تلگرامی درس و یکی یک پاراگراف در وصف استاد تشکر و تقدیر نوشتن که وای چقدر شما باسوادید و خوب و من را از این رو به آن رو کردید. چند نفر دیگر هم چند خطی نوشتن و دیدم این دو رویی برای من غیرقابل تحمل بود و گروه رو ترک کردم که دیگه نبینم. بعد از ترک گروه به خودم گفتم نکنه استاد بد برداشت کرده باشه و ناراحت شده باشه و احیانا نمره کم کرده باشه، تو دلم به خودم گفتم نه بابا استاد به این چیزها اهمیت نمیده خیالت راحت باشه.
وقتی به تازگی ارشد قبول شده بودم، خیلی دوست داشتم با سال بالایی هام صحبت کنم و از تجربههاشون بشنوم که ابهام این دوره برام کمتر بشه و بتونم این دوره رو بهتر بگذرونم. امسال با اومدن ورودی های جدید بنظرم وقتش رسیده بود که خودم مطالبی که به ذهنم میرسه رو در قالب یک پست بلاگ اینجا به اشتراک بگذارم. امیدوارم که مفید واقع بشه.
به روز شده ۱۹ دی ۱۴۰۰
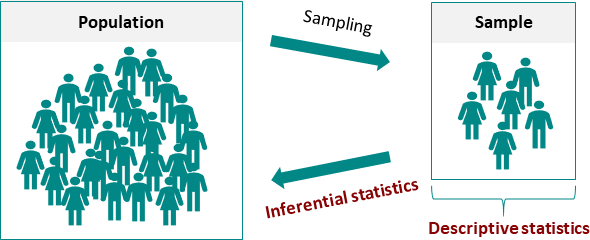
امروز فهمیدم میشه علم آمار رو به دو قسمت تقسیم کرد:
Inferential statistics
Descriptive statistics
در فارسی به Inferential statistics استنباط آماری میگن. این علم میتنونه رفتار یک جمعیت رو توضیح بده، از جز ب کل رسیدن. فرض کنید ما از چند نفر قد شون رو اندازه گیری کردیم و حالا میخواهیم راجع به قد آدمها نظر بدیم. اسم های دیگرش هم آمار هست. و ما قراره مقادیری رو تخمین بزنیم.
و به بخش دوم یعنی Descriptive statistics آمار توصیفی میگن، و این علم قراره رفتار نمونهای از یک جمعیت آماری رو توصیف کنه از کل به جز رسیدن. به عبارت دیگه من اطلاعات همه آدمها رو دارم و حالا میخواهم راجع به احتمال قد ۱۶۰ تا ۱۷۰ سانتیمتر نظر بدم. به این علم احتمال هم میگن.
البته هر کدوم از این علمها زیر بخش های خودشون رو دارن.
در این شکل که در اینجا(+) دیدمش میتونید بهتر با مفهوم این دو علم آشنا بشید.
۱۵ دقیقه اول جلسه ۱۹م این درس.
یکی از روزهای تابستون ۹۸ تصمیم گرفتم با دوچرخه از نیشابور به مشهد برم و برگردم. چرا؟ چون همیشه دوست داشتم با دوچرخم جاهای دور برم مثلا یادمه قبلترها دورترین جا شادیاخ-یک سایت تاریخی نزدیکی آرامگاه عطار حدود ۳ کیلومتری مرکز شهر- بود بعد شد بوژان-روستایی سرسبز با رودخانهها و چشمههای پر آب در شمال شرق نیشابور حدود 20 کیلومتری شهر- و حالا قصد داشتم به مشهد-شهری در شمال شرق نیشابور با فاصله 120 کیلومتری :)- برم. یکی دیگه از آدمهایی که بهم انرژی این سفر رو داد فرانسیس بود دیدن او و گپ زدن با او من مشتاق این سفر کرده بود.
در گذشته برای خوندن مقاله بعد از پیدا کردن و دریافتش شروع میکردم به خوندن از عنوان مقاله تا نتیجه گیری. اما خیلی زود فهمیدم این روش جواب نمیده چرا که واقعا به بعضی از اطلاعات اون وسط مقاله احتیاجی نداشتم، دیدن تصاویر مقاله کمک میکرد ساختار بهتری از آزمایشی که انجام بدن بدست بیارم و این طوری خوندن واقعا زمان زیادی میگرفت از من. و دیگه اینکه به مقالات review بیشتر از اون مقداری که لازمه اهمیت میدادم در حالی که بعدها فهمیدم اگه یک مقاله به خوبی نوشته شده باشه در همون قسمت introduction اطلاعات خوبی از پیشینه پژوهش بدست میاریم.
معمولا بعد از دریافت مقاله ابتدا عنوان رو میخونم و بعد هم چکیده یا abstract بعد از خوندن چکیده میپرم سمت تصاویر، به محورها دقت میکنم و فکر میکنم ببینم تصویر چی داره میگه بعد از اینکه برای خودم فکر کردم اگه برام مبهم بود زیرنویس تصویر رو هم میخونم تا دید بهتری داشته باشم.
پس از تصاویر هم میرم به دنبال نتیجهگیری یا Conclusion و اونجا رو هم اسکن میکنم. تا اینجا میتونم تصمیم بگیرم مقالهای که پیدا کردم آیا ارزشش رو داره بیشتر عمیق بشم یا در همین حد کافیه؟ اگه تصمیم گرفتم به کارم بیاد حالا میشنم از اول دوباره میخونم. پس تا اینجای کار فهمیدیم وقتی میگیم مقاله فلان رو خوندم به این معنی نیست که از عنوان تا مراجع همه رو کلمه به کلمه خونده باشیم، این کار خیلی کم پیش میاد و احتمالا مقاله های most related رو این طوری میخونیم. در این حالت میگن اصطلاحا مقاله رو با میکروسکوپ خوندنم :) از طرفی شما میتونی بگی فلان مقاله رو خوندم و منظورت این باشه که فقط عنوان و چکیده رو خوندی و خوب احتمالا خیلی به کارت نمیومده که ادامش ندادی.
ایشون تو یکی از کلاسهاشون این توصیه رو میکرد به بچهها در خوندن مقاله، بگردین و دنبال جواب این سوالها باشین به ترتیب
سوالی که این مقاله دنبالش بوده چی هست؟
اگه به درستی نوشته شده باشه باید جواب این سؤال رو توی چکیده پیدا کنید
چه جوابی برای اون سؤال پیدا کردن؟
باز هم اگه مقاله به درستی نوشته شده باشه باید بتونید جواب این سؤال رو در چکیده پیدا کنید
تفسیر جواب چی میشه یا به عبارت دیگه خب که چی؟
و باز هم اگه مقاله به درستی نوشته شده باشه باید بتونید جواب این سؤال رو در چکیده پیدا کنید
طراحی آزمایش شون چطور بوده یا دقیقا چیکار کردن؟
از اینجا دیگه ممکنه جواب این سؤال رو توی چکیده پیدا نکنید و لازم باشه برین بقیه مقاله رو بخونید البته دقت کنید حتی تو بعضی از مقالهها هم ممکنه جواب سه سؤال اول رو تو چکیده پیدا نکنید
دادهها چطور تحلیل شدن؟
چرا سوالی که مقاله به دنبالش رفته مهمه؟
معمولا جواب این سؤال هم در قسمت introduction بیان شده
و سه نکته:
- نگین این که ۵ صفحه مقالس پس ۲۰ دقیقه بیشتر وقتمو نمیگیره، خیر، حتی برای خود محققهای باتجربه هم گاهی همون ۵ صفحه نیاز به صرف مثلا ۵ ساعت وقت هست.
- لازم نیست اون قسمت که میان دستگاه شون رو معرفی میکنن و شرایطش رو میگن بخونید یا حداقل جدی بخونید.
- از اینکه دانش تحلیل دادههاتون قوی نیست نترسین و نگید که من باید دقیقا صفر تا صد تحلیل دادهها رو بفهمم، نه، در حد اینکه مثلا با بعضی از تستهای آماری مثل t-test یا ANOVA و یا با مفهوم Corrolation آشنا باشید کافیه بقیه تحلیلهای مقاله رو صرفا اگه شهودی هم بهش داشته باشین کافیه. منظورم از شهود چیه؟ مثلا اگه گفته با SVM دادهها مو برچسب زدم، همینه که شما بدونید SVM یک روش طبقهبندی هست کافیه.
حالا با داشتن این چهارچوب در ذهن تون بهتر میتونید به دنبال خوندن مقاله برین
من هم اینجا یک نمونه اوردم از این مقاله. که سؤال مقاله رو قرمز کردم جوابی که پیدا کردن رو سبز کردم و تفسیر جواب رو نارنجی.
شما هم یک مقاله انتخاب کنید و سعی کنید دنبال جواب حداقل این سه سؤال(سؤال/جواب/تفسیر) در چکیده بگردین.
منبع(چند دقیقه آخر این کلاس +)
امروز صبح چند ساعتی همین تابع addpath وقتم رو گرفت یک اسکریپت رو چند بار اجرا میکردم و هی میگفت که فلان تابع رو نمیشناسم. و بالاخره تونستم با یک دستور حل کنم و چند تا چیز هم یاد بگیرم.
خب وقتی کدهای شما بزرگتر میشن طبق اصول مهندسی نرمافزار بهتره بشکنیدشون به چند تا تابع کوچیک تر در فایلهای دیگه مثلا یک برنامه بزرگ مثل eeglab که وظیفه پردازش سیگنالهای مغزی رو داره از چندین تابع تشکیل شده.
خب path به معنی آدرس هست. هر فایلی یکpathی برای خودش داره
مفهوم Working directory. هر جا دستورات و یا فایل متلبتون رو دارین اجرا میکنید میشه پوشه کاری تون.
از کجا بدونیم پوشه کاریم چیه؟ با دستورpwd
آدرس دهی ها میتونن دول مدل نسبی و مطلق باشن در مدل آدرس دهی مطلق وقتی میخوایم یک m فایل رو آدرس بدیم مثلا اینجوری صداش میزنیم.
C:\Users\Amir\Documents\w\CNSP\my_mfile.m
در مدل آدرس دهی نسبی اگه پوشه کاریمون
C:\Users\Amir\Documents\w\CNSP
باشه کافیه فقط اسم تابع مون رو بنویسیم یعنی my_mfile
چطوری پوشه کاری مو به یا آدرس دیگه عوض کنم؟ با دستور cd که جلوش داخل کوتیشن آدرس جدید تون رو بنویسید.
یک مفهوم دیگه داریم به نام Search Path. بذارین بهش بگیم آدرس جستجو، وقتی مثلا تو m فایل تون یک تابع دیگه رو صدا میزنید اولی میره پوشه کاری رو میگرده ببینه میتونه پیداش کنه یا نه اگه بود استفاده میکنه و گرنه بهتون خطا میده.
خب حالا دستور addpath چیمیگه؟ فرض کنید یک پوشه دارین به اسم my_handy_functions که توش کلی m فایل و تابع های کاربردی دارین یک تابع برای فیلتر کردن یک تابع برای رسم نمودار یک تابع برای محاسبه میانگین سیگنال. وقی بخواین از تابع هاتون استفاده کنید که توی اون پوشه هستن برای اینکه هی نگنین من فلان تابعی رو میخوام که توی فلان پوشه هست و فقط اسم تابع رو بنویسید به متلب میگید:
addpath my_handy_function
حالا کافیه تنها اسم تابع تون رو بنویسید و متلب اون تابع رو میشناسه.
ولی توجه داشته باشین که اگه حجم m فایلهاتون بیشتر باشه توی پوشه my_handy_fuction با درست کردن چند پوشه مثل filtering_functions و Rerefrence و ploting داشته باشین تو توی هر کدوم چند m فایل دیگه متلب اونها رو نمیشناسه فقط هرچی توی my_handy_function هست رو میشناسه. به عبارت دیگه اگه بخواین یک پوشه و تمام پوشههای داخلی شو به path اضافه کنید از این دستور میتونید استفاده کنید
addpath(genpath('CNSP_tutorial\libs\eeglab'));
تابع genpath میره و زیر پوشهها رو پیدا میکنه و حالا هرچی فایل تو پوشه و زیر پوشههاش باشه توسط مطلب شناخته میشه.
نمیشه اینا رو گرافیکی انجام داد؟ چرا کافیه مطابق تصویر زیر به Home و بعد Set Path برین و مطابق نیاز تون از Add Folder یا Add with Subfolders استفاده کنید.
در ضمن اون کادر سبز رنگ یعنی پنجره Current folder هم کمک میکنه به شما که بدونیم مطلب چه آدرسهایی رو میشناسه اونفایلها و پوشههایی که رنگ شون روشنه یعنی متلب اونها رو میشناسه ولی اگه مثل NoiseTools رنگشون تیره باشه یعنی مطلب اونها رو نمیشناسه.

۱- قالب تمرین درسهای ارشد در فرمت مقاله
چند نکته غیر لاتکی راجع به تمرین:
۲- سمینار کارشناسی ارشد
۳- گزارش سهماهه کارشناسی ارشد
هر سه قالب رو میتونید با این لینک(+) دریافت کنید.
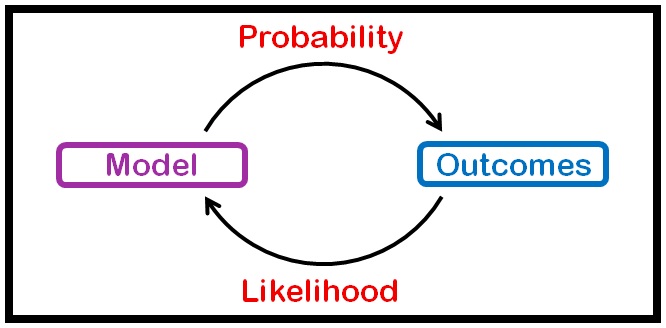
یک وقت هست شما میخوای بدونی سکه که میندازی شیر میاد یا خط، میگی احتمال شیر اومدن ۰.۵ هست. بعضی وقتها نه کلی داده جمع کردی از پرتاب یک سکه میخوای ببینی آیا سکه سالم بوده؟ یعنی احتمال شیر اومدن ۰.۵ بوده اون وقت میری سراغ تابع درستنمایی یا لایکلیهود. به عبارت دیگه در حالت اول دنبال پیش بینی آینده هستی و در حال دوم دنبال پیدا کردن مدل.

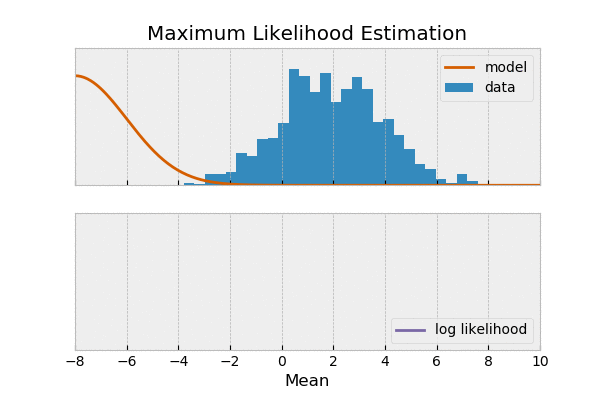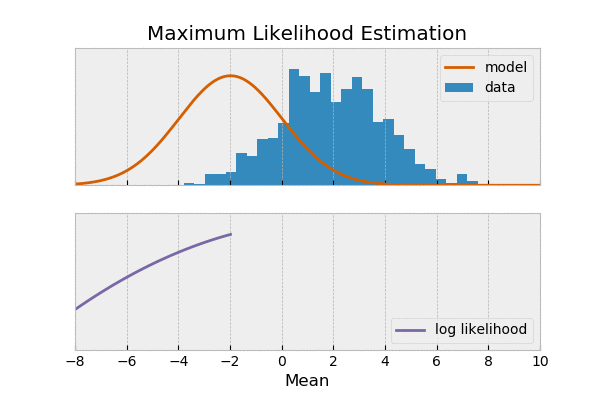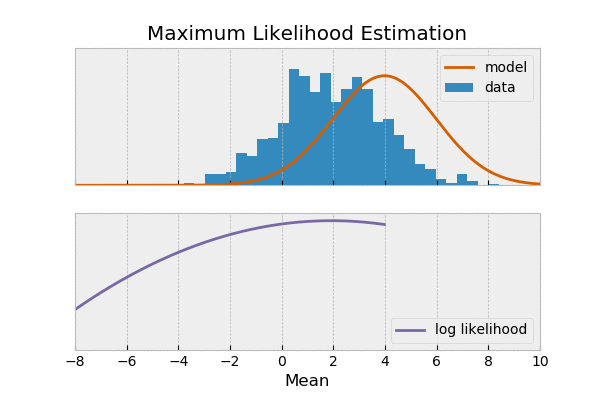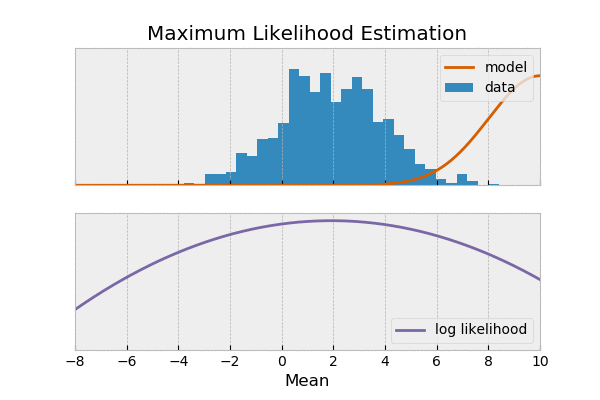
مثال: فرض کنید شیرین و ملیحه آشپزی کردن شیرین دوست داره غذای های شکری درست کنه و ملیحه هم دوست داری غذاهای نمکی درست کنه. دیشب شیرین، فالوده درست کرده ملیحه هم نودل،
در حالت احتمال شما مدل رو داری یعنی مثلا شیرین پیشته و سوالت این هست که چقدر احتمال داره شیرین یک غذای شور درست کنه
ولی در حالت لایکلی هود یک مشاهده داری یعنی مثلا غذا رو دیدی یا خوردی مثلا نودل رو حالا سوالت اینه که چقدر احتمال داره دست پخت شیرین باشه؟
تو اینجا شیرین و ملیحه همون مدل هستن و غذاهاشون داده.
مثال: سنجش میگه ۶۰ درصد کنکوریها خانم و ۴۰ درصد آقا هستن(مدل یا جامعه من). حالا من میرم دوربین ورودی دانشگاه رو میبینم برای یک ساعت(نمونه یا داده من). احتمال اینه که بگیم نسبت خانم و آقا در دوربین چیه؟ ولی یک وقت هست کار پیچیده تره و من به مدل یا جامعه دستری ندارم، مثلا بهداشت میگه ما از شهر چابهار ۱۰۰ نمونه کرونا گرفتیم و دیدیم ۱۰ نفر مبتلا هستن. حالا چقدر احتمال داره نصف شهر درگیر باشن؟ این سؤال دوم که از نمونه میخوایم برسیم به جامعه از جنس لایکلیهود هست.

چند تا نکته راجع به نحوه نوشتن:
مطالعه بیشتر (+)
به روزرسانی ۲۶امرداد۱۴۰۰
این فیلم رو هم آماده کردم که میتونید ببینید.
در ادامه مطلب به این میپردازیم که چطور داده هامون رو با یک خط بیان کنیم.
پس بیاین عبارت مشابهی که به این منظور استفاده میشن رو با هم بشناسیم تا از این به بعد هرجا دیدیمشون بدونیم از چی دارن حرف میزنن:
فرض کنید یک سری داده جمع کردین مثل اینها
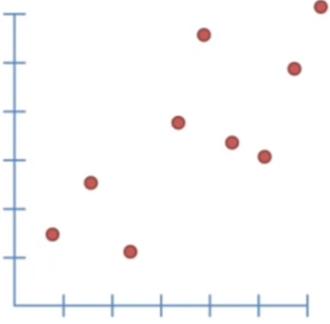
تصویر۱: دادههای ما مثل محور افقی میتونه پول باشه و محور عمودی آش دریافت شده (هرچقدر پول بدی همونقدر آش میخوری)
و حالا ما میخوایم یک خط رو روی اینا فیت(براز/نگاشت) کنیم ببینیم ترند(روند) دادهها چطوریه، سوالی که مطرح میشه این هست که خوب کدوم از همه بهتره؟